











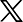

 |
| 자료=김종락 서강대 수학과 교수 연구팀 / 그래픽= 박종규 기자 |
김종락 서강대 수학과 교수 연구팀은 국내 '국가대표 AI' 도전에 참여한 5개 팀의 LLM과 챗GPT 등 해외 주요 모델 5개를 대상으로 수학 문제 풀이 성능을 비교한 결과를 15일 공개했다.
이번 연구는 서강대 수리과학 및 데이터사이언스 연구소(IMDS)와 딥파운틴의 공동 지원으로 수행됐다.
연구팀은 수능 수학에서 공통과목, 확률과 통계, 미적분, 기하 영역 중 최고 난도 문항 5개씩 총 20문제를 선정했다. 논술 문제는 국내 10개 대학 기출 문제 10문제, 인도 대학입시 문제 10문제, 일본 도쿄대 공대 대학원 입시 수학 문제 10문제 등 총 30문제를 구성했다. 총 50문제를 10개 모델에 동일하게 풀게 했다.
국내 모델로는 업스테이지의 '솔라 프로-2', LG AI연구원의 '엑사원 4.0.1', 네이버의 'HCX-007', SK텔레콤의 'A.X 4.0(72B)', 엔씨소프트의 경량 모델 '라마 바르코 8B 인스트럭트'가 사용됐다. 해외 모델은 GPT-5.1, 제미나이3 프로 프리뷰, 클로드 오푸스 4.5, 그록 4.1 패스트, 딥시크 V3.2 등이었다.
평가 결과 해외 모델은 76~92점을 기록한 반면, 국내 모델은 '솔라 프로-2'만 58점을 받았고 나머지는 20점대에 머물렀다. 특히 '라마 바르코 8B 인스트럭트'는 2점으로 가장 낮은 점수를 기록했다. 연구팀은 국내 모델의 경우 단순 추론만으로는 문제 해결이 어려워 파이선(Python) 도구 사용을 허용했음에도 점수 차이가 크게 벌어졌다.
연구팀은 이어 자체 제작한 수학 문제 세트 '엔트로피매스(EntropyMath)' 100문제 중 10문제를 활용해 추가 평가를 진행했다. 이 문제 세트는 대학교 수준부터 교수급 연구 난이도까지 세분화해 구성됐다. 이 평가에서도 해외 모델은 82.8~90점을 기록한 반면, 국내 모델은 7.1~53.3점에 그쳤다.
세 차례 시도해 정답을 맞히면 통과하는 방식의 추가 실험에서는 그록이 만점을 받았고, 다른 해외 모델들도 90점을 기록했다. 국내 모델은 솔라 프로-2가 70점, 엑사원이 60점, HCX-007이 40점, A.X 4.0이 30점, 라마 바르코 8B 인스트럭트가 20점에 머물렀다.
김 교수는 "국내 5개 소버린 AI 모델에 대한 수능 수학 평가가 왜 없는지 묻는 목소리가 많아 자체 테스트를 진행했다"며 "해외 프런티어 모델과 비교해 국내 모델의 수학적 추론 능력이 많이 뒤처져 있음을 확인했다"고 밝혔다.
연구팀은 이번에 사용된 국내 모델이 모두 기존에 공개된 버전이라는 점을 강조하며, 각 팀의 국가대표 AI 최신 버전이 공개되면 자체 개발한 문제를 활용해 다시 성능을 평가할 계획이라고 덧붙였다.






